

The Future of Deep Learning Can Be Broken Down Into These 3 Learning Paradigms

The Future of Deep Learning Can Be Broken Down Into These 3 Learning Paradigms
Hybrid, Composite, & Reduced Learning
Original website:
Deep learning is a vast field, centered around an algorithm whose shape is determined by millions or even billions of variables and is constantly being altered — the neural network. It seems that every other day overwhelming amounts of new methods and techniques are being proposed.
In general, however, deep learning in the modern era can be broken down into three fundamental learning paradigms. Within each lies an approach and belief towards learning that offers significant potential and interest to increasing the current power and scope of deep learning.
Hybrid learning — how can modern deep learning methods cross the boundaries between supervised and unsupervised learning to accommodate for a vast amount of unused unlabeled data?
Composite learning — how can different models or components be connected in creative methods to produce a composite model greater than the sum of its parts?
Reduced learning — how can both the size and information flow of models be reduced, both for performance and deployment purposes, while maintaining the same or greater predictive power?
The future of deep learning lies in these three paradigms of learning, each of which are heavily interconnected.
Hybrid Learning
This paradigm seeks to cross boundaries between supervised and unsupervised learning. It is often used in the context of business because of the lack and high cost of labelled data. In essence, hybrid learning is an answer to the question,
How can I use supervised methods to solve/in conjunction with unsupervised problems?
For one, semi-supervised learning is gaining ground in the machine learning community for being able to perform exceptionally well on supervised problems with few labelled data. For example, a well-designed semi-supervised GAN (Generative Adversarial Network) achieved over 90% accuracy on the MNIST dataset after seeing only 25 training examples.
Semi-supervised learning is designed for datasets where there is a lot of unsupervised data but small amounts of supervised data. Whereas traditionally a supervised learning model would be trained on one part of the data and an unsupervised model the other, a semi-supervised model can combine labelled data with insights extracted from unlabeled data.
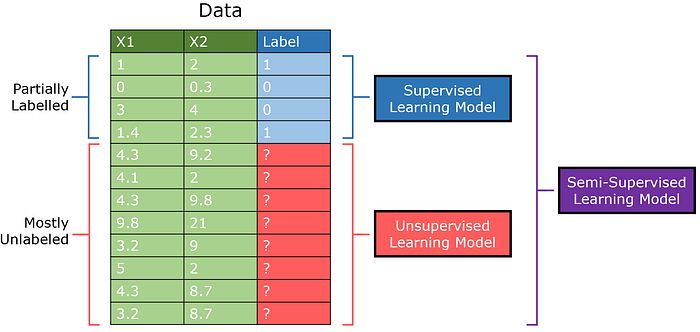
The semi-supervised GAN (abbreviated as SGAN), is an adaptation of the standard Generative Adversarial Network model. The discriminator both outputs 0/1 to indicate if an image is generated or not, but also outputs the class of the item (multioutput learning).
This is premised on the idea that through the discriminator learning to differentiate between real and generated images, it is able to learn their structures without concrete labels. With additional reinforcement from a small amount of labelled data, semi-supervised models can achieve top performances with minimal amounts of supervised data.
You can read more about SGANs and semi-supervised learning here.
GANs are also involved in another area of hybrid learning — self-supervised learning, in which unsupervised problems are explicitly framed as supervised ones. GANs artificially create supervised data through the introduction of a generator; labels are created to identify real/generated images. From an unsupervised premise, a supervised task was created.
Alternatively, consider the usage of encoder-decoder models for compression. In their simplest form, they are neural networks with a small amount of nodes in the middle to represent some sort of bottleneck, compressed form. The two sections on either side are the encoder and decoder.
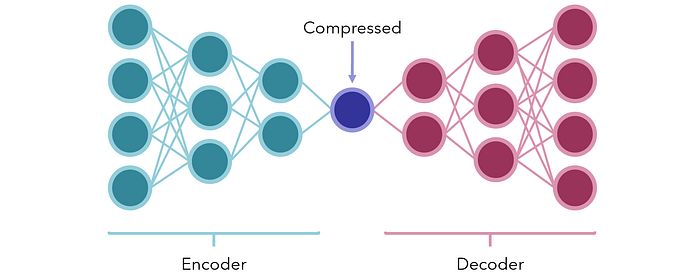
The network is trained to produce the same output as the vector input (an artificially created supervised task from unsupervised data). Because there is a deliberately placed bottleneck in the middle, the network cannot passively pass the information along; instead, it must find the best ways to preserve the content of the input into a small unit such that it can be reasonably decoded again by the decoder.
After trained, the encoder and decoder are taken apart and can be used on receiving ends of compressed or encoded data to transmit information in extremely small form with little to no lost data. They can also be used to reduce the dimensionality of data.
As another example, consider a large collection of texts (perhaps comments from a digital platform). Through some clustering or manifold learning method, we can generate cluster labels for collections of texts, then treat these as labels (provided that the clustering is well done).
After each cluster is interpreted (e.g. cluster A represents comments complaining about a product, cluster B represents positive feedback, etc.) a deep NLP architecture like BERT can then be used to classify new texts into these clusters, all with completely unlabeled data and minimal human involvement.
This is yet again a fascinating application of converting unsupervised tasks into supervised ones. In an era where the vast majority of all data is unsupervised data, there is tremendous value and potential in building creative bridges to cross the boundaries between supervised and unsupervised learning with hybrid learning.
Composite Learning
Composite learning seeks to utilize the knowledge not of one model but of several. It is the belief that through unique combinations or injections of information — both static and dynamic — deep learning can continually go deeper in understanding and performance than a single model.
Transfer learning is an obvious example of composite learning, and is premised on the idea that a model’s weights can be borrowed from a model pretrained on a similar task, then fine-tuned on a specific task. Pretrained models like Inception or VGG-16 are built with architectures and weights designed to distinguish between several different classes of images.
If I were to train a neural network to recognize animals (cats, dogs, etc.), I wouldn’t train a convolutional neural network from scratch because it would take too long to achieve good results. Instead, I’d take a pretrained model like Inception, which has already stored the basics of image recognition, and train for a few additional epochs on the dataset.
Similarly, word embeddings in NLP neural networks, which map words physically closer to other words in an embedding space depending on their relationships (e.g. ‘apple’ and ‘orange’ have smaller distances than ‘apple’ and ‘truck’). Pretrained embeddings like GloVe can be placed into neural networks to start from what is already an effective mapping of words to numerical, meaningful entities.
Less obviously, competition can also stimulate knowledge growth. For one, Generative Adversarial Networks borrow from the composite learning paradigm by fundamentally pitting two neural networks against each other. The generator’s goal is to trick the discriminator, and the discriminator’s goal is not to be tricked.
Competition among models will be referred to as ‘adversarial learning’, not to be confused with another type of adversarial learning that refers to the designing of malicious inputs and exploiting of weak decision boundaries in models.
Adversarial learning can stimulate models, usually of different types, in which the performance of a model can be represented in relation to the performance of others. There is still a lot of research to be done in the field of adversarial learning, with the generative adversarial network as the only prominent creation of the subfield.
Competitive learning, on the other hand, is similar to adversarial learning, but is performed on the node-by-node scale: nodes compete for the right to respond to a subset of the input data. Competitive learning is implemented in a ‘competitive layer’, in which a set of neurons are all the same, except for some randomly distributed weights.
Each neuron’s weight vector is compared to the input vector and the neuron with the highest similarity, the ‘winner take all’ neuron, is activated (output = 1). The others are ‘deactivated’ (output = 0). This unsupervised technique is a core component of self-organizing maps and feature discovery.
Another interesting example of composite learning is in neural architecture search. In simplified terms, a neural network (usually recurrent) in a reinforcement learning environment learns to generate the best neural network for a dataset — the algorithm finds the best architecture for you! You can read more about the theory here and implementation in Python here.
Ensemble methods are also a staple in composite learning. Deep ensemble methods have shown to be very effective, and the stacking of models end-to-end, like encoders and decoders, has risen in popularity.
Much of composite learning is figuring out unique ways to build connections between different models. It is premised on the idea that,
A single model, even one very large, performs worse than several small models/components, each delegated to specialize in part of the task.
For example, consider the task of building a chatbot for a restaurant.

We can segment it it into three separate parts: pleasantries/chit-chat, information retrieval, and an action, and design a model to specialize in each. Alternatively, we can delegate a singular model to perform all three tasks.
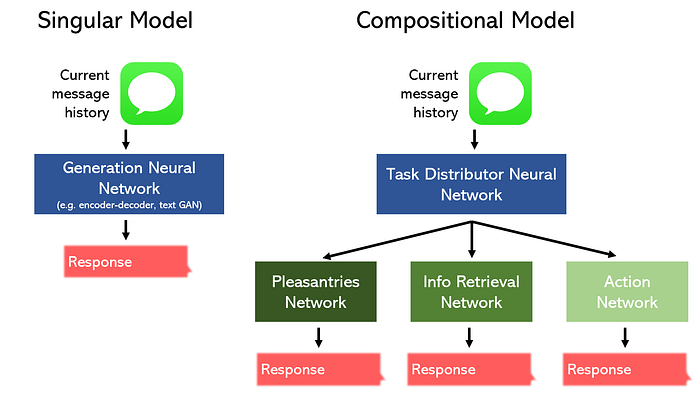
It should be no surprise that the compositional model can perform better while taking up less space. Additionally, these sorts of nonlinear topologies can be easily constructed with tools like Keras’ functional API.
In order to process an increasing diversity of data types, like videos and 3-dimensional data, researchers must build creative compositional models
Read more about compositional learning and the future here.
Reduced Learning
The size of models, particularly in NLP — the epicenter of flurried excitement in deep learning research — is growing, by a lot. The most recent GPT-3 model has 175 billion parameters. Comparing it to BERT is like comparing Jupiter to a mosquito (well, not literally). Is the future of deep learning bigger?
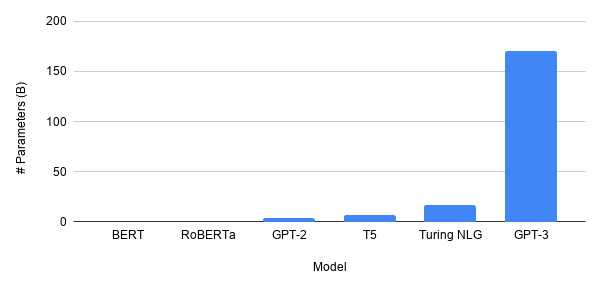
Very arguably, no. GPT-3 is very powerful, admittedly, but it has shown repeatedly in the past that ‘successful sciences’ are ones that have the largest impact on humanity. Whenever academia strays too far from reality, it usually fades into obscurity. This was the case when neural networks were forgotten in the late 1900’s for a brief period of time because there was so little available data that the idea, however ingenious, was useless.
GPT-3 is another language model, and it can write convincing text. Where are its applications? Yes, it could generate, for instance, answers to a query. There are, however, more efficient ways to do this (e.g. traverse a knowledge graph and use a smaller model like BERT to output an answer).
It simply just does not seem to be the case that GPT-3’s massive size, not to mention a larger model, is feasible or necessary given a drying up of computational power.
“Moore’s Law is kind of running out of steam.”
- Satya Nadella, CEO of Microsoft
Instead, we’re moving towards an AI-embedded world, where a smart refrigerator can automatically order groceries and drones can navigate entire cities on their own. Powerful machine learning methods should be able to be downloaded onto PCs, mobile phones, and small chips.
This calls for lightweight AI: making neural networks smaller while maintaining performance.
It turns out that, directly or indirectly, almost everything in deep learning research has to do with reducing the necessary amount of parameters, which goes hand-in-hand with improving generalization and hence, performance. For example, the introduction of convolutional layers drastically reduced the number of parameters needed for neural networks to process images. Recurrent layers incorporate the idea of time while using the same weights, allowing neural networks to process sequences better and with less parameters.
Embedding layers explicitly map entities to numerical values with physical meanings such that the burden is not placed on additional parameters. In one interpretation, Dropout layers explicitly block parameters from operating on certain parts of an input. L1/L2 regularization makes sure a network utilizes all of its parameters by making sure none of them grows too large and that each maximizes their information value.
With the creation of specialized layers, networks require less and less parameters for more complex and larger data. Other more recent methods explicitly seek to compress the network.
Neural network pruning seeks to remove synapses and neurons that don’t provide value to the output of a network. Through pruning, networks can maintain their performance while removing almost all of itself.
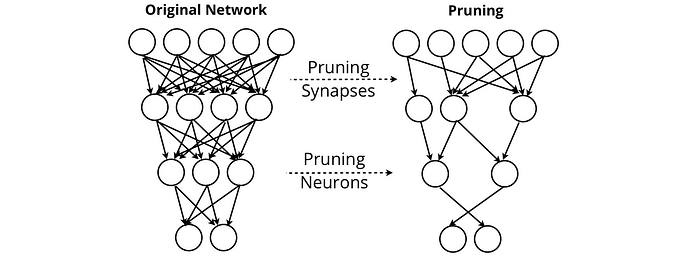
Other methods like Patient Knowledge Distillation find methods to compress large language models into forms downloadable onto, for example, users’ phones. This was a necessary consideration for the Google Neural Machine Translation (GNMT) system, which powers Google Translate, which needed to create a high-performing translation service that could be accessed offline.
In essence, reduced learning centers around deployment-centric design. This is why most research for reduced learning comes from the research department of companies. One aspect of deployment-centric design is not to blindly follow performance metrics on datasets, but to focus on potential issues when a model is deployed.
For instance, previously mentioned adversarial inputs are malicious inputs designed to trick a network. Spray paint or stickers on signs can trick self-driving cars to accelerating well over the speed limit. Part of responsible reduced learning is not only making models lightweight enough for usage, but ensuring that it can accommodate for corner cases not represented in datasets.
Reduced learning is perhaps getting the least attention of research in deep learning, because “we managed to achieve good performance with a feasible architecture size” isn’t nearly as sexy as “we achieve state-of-the-art performance with an architecture consisting of kajillions of parameters”.
Inevitably, when the hyped pursuit of a higher fraction of a percentage dies away, as the history of innovation as shown, reduced learning — which is really just practical learning — will receive more of the attention it deserves.
Summary
Hybrid learning seeks to cross the boundaries of supervised and unsupervised learning. Methods like semi-supervised and self-supervised learning are able to extract valuable insights from unlabeled data, something incredibly valuable as the amount of unsupervised data grows exponentially.
As tasks grow more complex, composite learning deconstructs one task into several simpler components. When these components work together — or against each other — the result is a more powerful model.
Reduced learning hasn’t received much attention as deep learning rides out a hype phase, but soon enough practicality and deployment-centric design will emerge.
Thanks for reading!
Statement: for academic exchange only. The copyright of this article belongs to the original author. If there is anything wrong, please contact to delete.